
LangChain provides the dependencies for building applications that can answer queries asked by the user in natural languages. The user needs to train the language models using the template or structure for the queries so the models can start working as soon as it detects the question from the format. The model understands the question first and then extracts the answer from different sources using the tools attached to the agents.
The platform offers the use of callbacks and their handlers so the agent can work through each step according to the need and its time in the structure. If the orientation of the format is not followed properly then the answers can be illogical and misinterpreted more often than not. To avoid these complications the LangChain allows the user to configure and use the agents or chains with Callback Handlers.
What are CallbackHandlers in LangChain
The Callback handlers in LangChain are configured using the BaseCallbackhandler which can be used to call different handlers for the Callback. Different Callback methods are used for different purposes and at different moments in the process to make sure that each step is working at its proper time. Some of the important CallbackHandlers are mentioned below:
on_llm_start(): it starts working when the language model gets invoked to extract information for the user
on_chat_model_start(): it is associated with the chat_model so it will be executed for the chat models in LangChain
on_llm_new_token(): it is available when the streaming is enabled for the LLM and starts running when the new token appears in the streaming
on_llm_end(): it works when the language model finishes its working in the LangChain model
on_llm_error(): it is invoked when the language model generates some error as something goes beyond its scope, etc.
on_chain_start(): it starts when the chain is executed in the LangChain model
on_chain_end(): works when the chain stops working in the model as its job is done for now
on_chain_error(): when chains are faced with an error at that moment it is executed
on_tool_start(): this callback method is called when the new tool is executed to perform any task
on_tool_end(): it is invoked when the tool finishes its tasks asked by the agent in the LangChain model
on_tool_error(): it starts running when the tool generates some error
on_text(): it is called when an arbitrary/random text is generated
on_agent_action(): it runs when the agent is in the running state which is the agent_action phase
on_agent_finish(): it runs when the agent stops working and goes to the agent_finish phase
The above section explained each CallbackHandler method in LangChain and now we move on to their syntaxes while building the LangChain models:
Syntax
The following code is for the CallbackHandler that can be used to manage all the above-mentioned callbacks in the LangChain language model:
class BaseCallbackHandler:
"""Base callback handler to manage callbacks using langchain"""The code defines the on_llm-start() method with a list of arguments that explain its functionality like prompts are part of the language model. So, the parameter suggests that the method should be called when the language model gets the prompt from the user. The start of the llm takes part in multiple stages explained by the arguments such as self, serialized, and prompts suggest:
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Runs when Language model is running"""The on_chat_model_start() method uses the message argument which is different from the previous section as the chat models don’t have commands. The chat models have the interface of the chat as the query from the user is considered as the message and the model responds accordingly:
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""starts working when Chat Model is running"""The on_llm_new_token() method is defined using the self, token, and **kwargs arguments to start its execution when a new token is produced:
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""Run on new LLM token Only available when streaming is enabled"""The on_llm_end() method uses the response argument with the LLMResults that suggests it starts working when the models as the results and the language model stops running:
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running"""The following code defines the on_llm_error() method with the Exception and KeyboardInterrupt argument suggesting that it should be executed when LLm faces some error:
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when LLM errors"""The on_chain_start() method is called when the chains begin their work as the arguments like serialized and inputs indicate:
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> Any:
"""Run when chain starts running"""The on_chain_end() is defined using the output argument which means that it should run when the chain stops working:
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any:
"""Run when chain ends running"""Defining the on_tool_start() method with the serialized and input_str means that the method should be called when the tool is being called by the agent to perform its tasks:
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> Any:
"""Starts working when the tool is running"""Running the on_tool_end() method means that the tool has stopped working and its job is completed:
def on_tool_end(self, output: str, **kwargs: Any) -> Any:
"""Run when tool ends running"""The on_tool_error() method with the exception and error arguments refers to the occurrence of an exception in the tool:
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Works when the tool faces some error"""The agents are executed as soon as the prompt is provided by the user to the model so the callback handler is defined with the name on_agent_action(). It starts working when the agent remains in action which is until an error occurs or the model generates the information:
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action"""The on_agent_finish() method runs when the agent stops working which means that it is looking for the prompt or message from the user:
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""Run on agent end"""The on_text() method is executed when the random text is generated as the model works systematically and the randomness of the text should be avoided. The arbitrary text does not make any sense most of the time so it should be handled accordingly:
def on_text(self, text: str, **kwargs: Any) -> Any:
"""Run on arbitrary text"""Where to Pass CallbackHandlers in LangChain
The LangChain offers callbacks for different components like language model, chain, tools, agents, etc. within only two places which are as follows:
Constructor Callbacks
It is defined in the argument of the constructor like LLMChain(callbacks=[handler]) and executed when the objects are called without acting for the models integrated into it. These callbacks are mostly used to get the logs of the processes of the model to monitor the steps involved in extracting information from the language model.
Request Callbacks
These callbacks are defined while running or executing the chains like a chain.run(callbacks=[handler]) method to be executed for requests and subrequests for the chain. These callbacks are used for generating streams of the tokens while printing the output on the screen.
How to Use CallbackHandlers in LangChain
To learn the process of using the CallbackHandler, the following steps explain the process in detail. The notebook that contains the code executed in Python is also provided here:
Step 1: Install Modules
First, install the LangChain framework using the following code which can be executed on any Python Notebook:
pip install langchain
Install the OpenAI with its specific version if the general command doesn’t work to get its dependencies for building the language model in LangChain:
pip install openai==0.28.1
Step 2: Setup OpenAI Environment
Once the modules are installed, simply set up the OpenAI environment by extracting the API key from its account and entering it on the execution of the following code:
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 3: Importing Libraries
After setting up the environment for building the Language model, get the libraries from the dependencies installed using the langChain framework:
from langchain.callbacks import StdOutCallbackHandlerfrom langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import OpenAI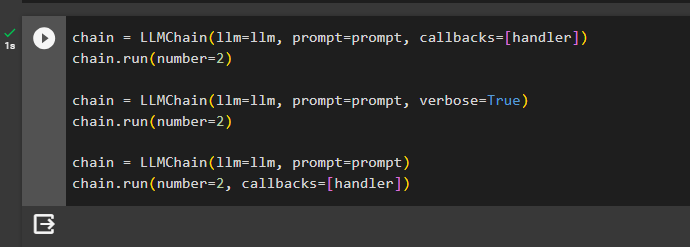
Step 4: Building Language Model
Define the built-in standard callback handler which is the StdOutCallbackHandler() to get the logs of all the actions and then build the language model using the OpenAI() method. Set the prompt structure for the language model to simply return the answer after adding one to the number provided by the user:
handler = StdOutCallbackHandler()
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")Step 5: Testing the Callback Handlers
The following code uses three chains to get the answer from the model by using callbacks differently in each chain:
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])#Constructor callbacks
chain.run(number=2)
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
chain.run(number=2)
chain = LLMChain(llm=llm, prompt=prompt)
chain.run(number=2, callbacks=[handler])#Request callbacksThe first chain simply uses the callback handler in its argument so it will run automatically but the interesting part is that the second chain does not pass the callbacks. However, the verbose flag is set to true which automatically invokes the callbacks without specifically passing in the argument. The last chain contains the callbacks argument while running the agent to get the answer from the model as well:
Output
The following screenshot displays that the three chains started and finished and only the third one produces the error. This is because the first two contain the callback while configuring chains and the last one uses it during the execution of the chain:
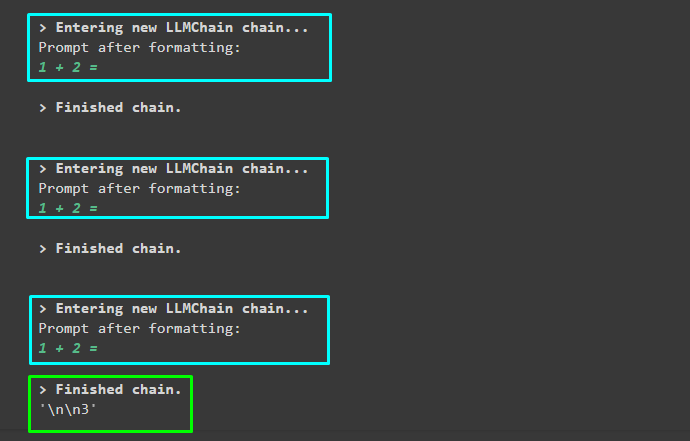
That’s all about the process of using the CallbackHandlers and its implementation in LangChain.
Conclusion
To use the CallbackHandler in LangChain, install the frameworks to get the dependencies for building the language model or chains. The dependencies can be used to import the libraries from the LangChain and OpenAI modules to configure the built-in callback Handler. The callbacks are used in two places like in the constructor method and while running the method to get the answer from the model. This guide explains the callback Handler in LangChain and its implementation in LangChain.