
The iPython is a command shell that provides a versatile experience for programmers to execute computational commands with rich commands and visualizations in a single environment. However, the coder is mostly interested in executing rich computational programs that process output without any interruption (stuck/shut down). In such scenarios, the iPython, an interactive command shell provides flexible access to users to execute computationally expensive programs.
This article will elaborate on how users can read an Excel (.xlsx) file using the Pandas Library in iPython.
Getting Started With Ipython Jupytor Notebook Environment
Ipython is part of the Anaconda Environment and provides a default kernel to its distributions like “Jupyter Notebook” (formerly known as Ipython NoteBook). For Jupyter Notebook or JupyterLab, the Ipython interactive Command Line is included as a default console. That gives flexible access to users to utilize all the features of IPython like handling high visualization commands, computationally expensive commands, and so on.
Note: You can download the Anaconda environment from its official link. And start using the IPython features.
After Launching the Jupyter Notebook, the command will redirect you to the default browser of your local host. It will always open with the “localhost:8888/tree” in your browser. However, “8888” is the default port number:
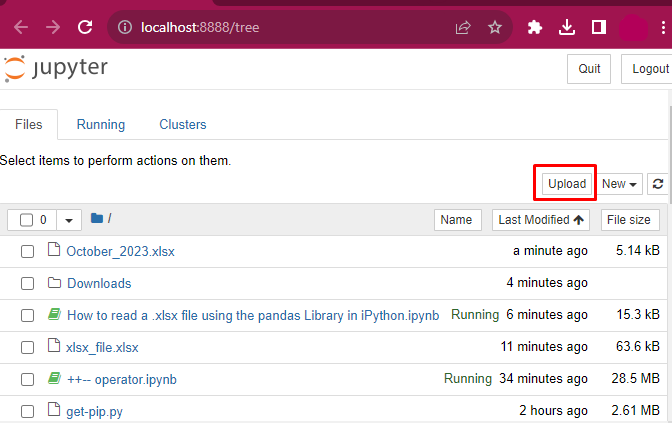
Creating a Notebook On Jupyter (IPython)
There are steps involved in creating a new iPython Notebook in the Jupyter. For demonstration, follow the below-listed set of instructions:
Step 1: Navigate to the “New” Option in Jupyter Notebook
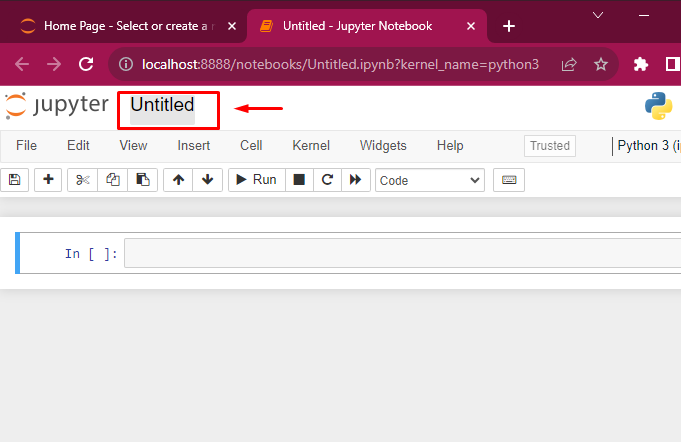
To create a Notebook, first search for the “Files” menu, then navigate to the “New” pull-down menu. From the Drop-down menu, click on the below highlighted “Python 3 (ipykernel)” option:
Step 2: Rename the Notebook
Click on the “Untitled” option accessible at the top-right of the Jupyter Notebook. Click on it to rename it:
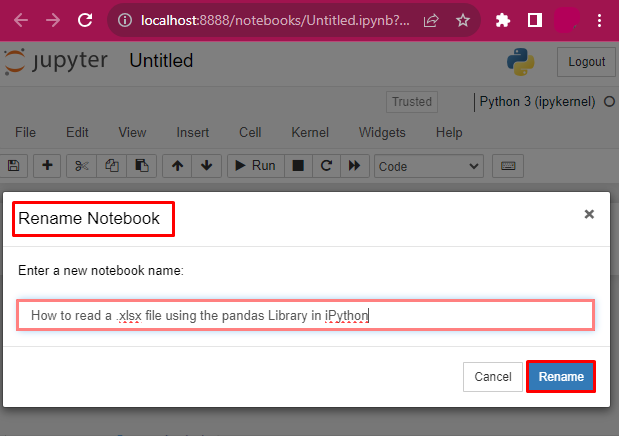
Step 3: Enter the New Notebook Name
The “Rename Notebook” wizard will prompt on the screen. The “Enter a new notebook name:” field provides a name for the Notebook to get started with the iPython Notebook:
How to Read a .xlsx file Using the Pandas Library in iPython?
In a real-world scenario, data is generated every second from the small store to the large enterprises. Companies and ventures are collecting and storing data in various formats for better data analysis and fetching useful insights from the data. The common and popular approach to storing the data is in Excel format. However, there are varieties in Excel to save data in either “.xlsx”, “.xlsb”, and so on. To get started with reading the “.xlsx” file in the iPython Notebook, follow the below-listed prevalent approaches:
- Reading the “.xlsx” File in the iPython Notebook
- Parsing the “.xlsx” File in the Dictionary in the iPython
- Get the Cell Information Of the “.xlsx” File in the iPython
- Reading the “.xlsx” File in List of Strings
Approach 1: Reading the “.xlsx” File in the iPython Notebook
The Ipython interface provides the flexibility to execute one command at a time and get results instantly upon execution. However, to load and read the “.xlsx” file in the iPython Notebook, follow the below-listed set of instructions:
Step 1: Import the Necessary Library
Upon launching the iPython Notebook, import the “pandas” library to the Jupyter Notebook (formerly named iPython Notebook). Utilize the “import” keyword to bring the library or module to the IDE script. Here for simplicity and conciseness the “pnd”, a shorthand name is used for the “pandas” library. However, you can use “pandas” instead:
#import pandas library to the ipython kernel
import pandas as pndStep 2: Load the “.xlsx” File
Next, load the “.xlsx” file to the iPython Script. To read the “.xlsx” file, utilize the “read_excel()” built-in function of the pandas library:
# loading the xlsx file using the read_excel() function
Read_xlsx = pnd.read_excel('Oct_23.xlsx')Step 3: Transform the Dataset To the DataFrame
Now, convert the dataset to the mutable 2-dimensional structure. To do so, utilize the “DataFrame()” function in Python:
# transforming the .xlsx file in the dataframe
DataFrame_xlsx = pd.DataFrame(Read_xlsx, columns=['List'])If you have not uploaded your “.xlsx” file to the iPython Notebook then you need to provide the path directory of the desired file. To load the file to the iPython Notebook script, use the “(r‘ ‘)” syntax, within the quotation (‘ ‘) provides the “.xlsx” file path, as shown in the below command:
#loading the xlsx file to the kernel
DataFrame = pnd.read_excel(r'C:\Users\CYBER WORLD\Oct_23.xlsx')Step 4: Printing the DataFrame on the Console
Printing the DataFrame on the iPython kernel console using the built-in “print()” function:
# Print the data on the sheet
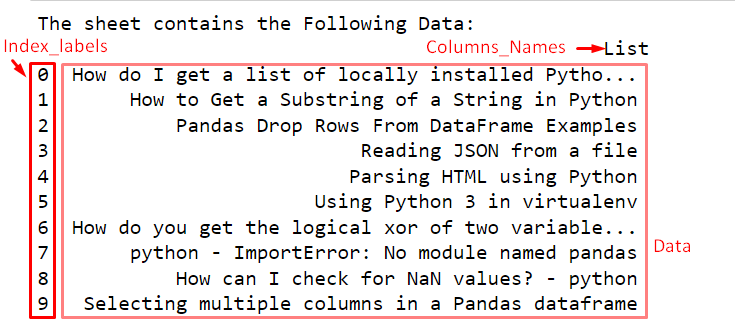
print('The sheet contains the Following Data:\n', DataFrame_xlsx)Output
By default the entire DataFrame is displayed on the iPython console:
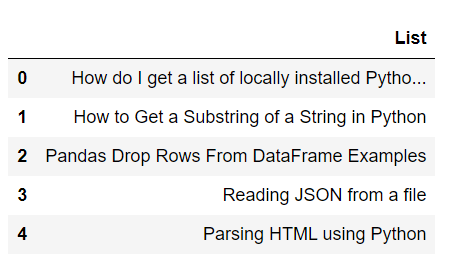
Step 5: Read the First Five Rows
However, if you want to display the first 5 rows from the DataFrame then utilize the pandas’s “head()” function:
#utilizing built-in head function to display first 5 rows from the dataframe to the kernel
DataFrame_xlsx.head()Output
The below snap illustrates the first five rows from the entire DataFrame on the console:
Approach 2: Parsing the “.xlsx” File in the Dictionary in the iPython
Another approach is to read the “.xlsx” file in the dictionary format. However, it is not necessary but it depends upon the user’s preference to read the file in dictionary format. To parse the DataFrame in the dictionary follow the below demonstrated example code:
#reading an Excel file into the ipython kernel
reading_xlsx_sheet = pnd.ExcelFile('Oct_23.xlsx')
#reading and converting DataFrame content to a dictionary
Dataframe = {sheet_name: reading_xlsx_sheet.parse(sheet_name)
for sheet_name in reading_xlsx_sheet.sheet_names}
#printing a Dataframe
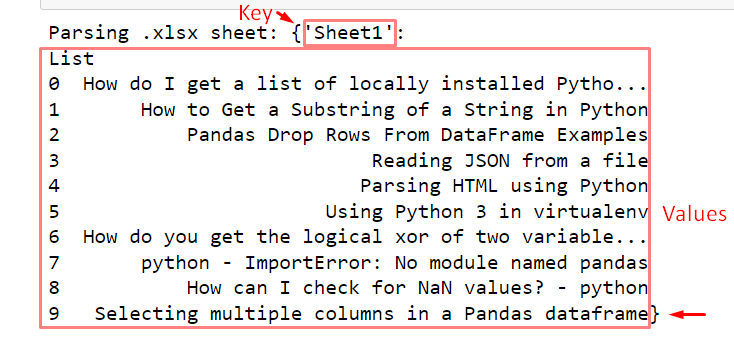
print('Parsing .xlsx sheet:', Dataframe)In the above example code, the dict parenthesis “{ }” is utilized to read and transform the “.xlsx” data using the pandas “ExcelFile()” function. The “ExcelFile()” reads the “.xlsx” file and uses the “sheet_name” parameter within the dictionary parenthesis ({ }) to transform the DataFrame into the dictionary format. By default “(‘sheet1’)” is the “key” assigned to the DataFrame and the entire data will become the “value”, hence completing the dictionary “key-value” pair.
Output
The below snap depicts that the “.xlsx” is read as the dictionary. However, the excel has one sheet only:
Approach 3: Get the Cell Information of the “.xlsx” File in the iPython
The openpyxl will return the “.xlsx” file by reading the cell by rows and columns and returning the output accordingly. However, to read the “.xlsx” file first, you need to activate the Dataframe sheet in the iPython Notebook. For this utilize the “active” attribute of the “DataFrame” using the dot(.) notation. Then using the for…in structure looping through the range function iterates the rows and columns sequence. The range function reads the file data to the maximum row and column data:
#import openpyxl library
import openpyxl
# loading the dataframe into the Python script using the load_workbook() function
DataFrame = openpyxl.load_workbook("October_2023.xlsx")
# fetching the active sheet dataframe
DataFrame = DataFrame.active
# Iterate the loop to read the sheet content and get cells from the sheet by rows
for row in range(0, DataFrame.max_row):
#fetch cells from the sheet by columns
for col in DataFrame.iter_cols(1, DataFrame.max_column):
#prints the value by iterating over rows and columns
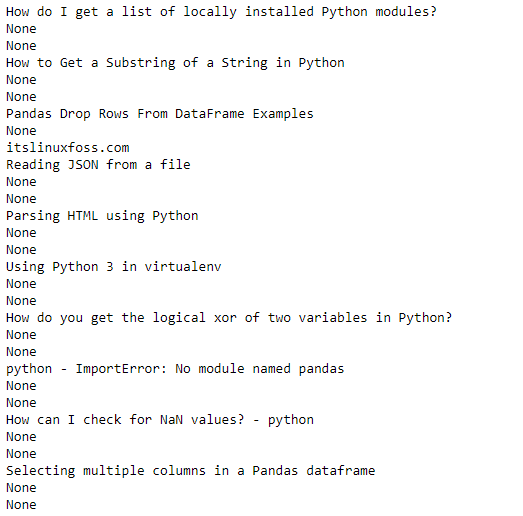
print(col[row].value) In the above example code, the “.xlsx” file is loaded and read in the iPython script using the “openpyxl” module. After reading the “.xlsx” file, utilize the nested for..in structure non-list comprehension structure to fetch the rows and columns data of the cell one after another.
Output
The openpyxl will load the “.xlsx” file to the iPython script and read it one by one by fetching the sheet cell information:
Approach 4: Reading the “.xlsx” File in List of Strings
The “xlwings” module will redirect the programmer to open and automate the “xlsx” Excel sheet on the pre-installed application of the local system. The “xlwings” module will read the “.xlsx” file and parse it to lists of strings format on the iPython kernel console. If you want to extract the “.xlsx” data in the form of lists of strings then utilize the “xlwings” module in Python. For demonstration, follow the below example code:
#redirect user to automate Excel sheet on Operating system
import xlwings as xlw
# Open the Workbook on the installed application on the local system
Workbook = xlw.Book("Oct_23.xlsx").sheets['Sheet1']
# fetching data from a single cell
Read_xlsx_data = Workbook .range("A1:A11").value
#printing the dataset and opens the workbook on the system's application(Excel spreadsheet)
print("Reading Xlsx Data:", Read_xlsx_data)The above example code reads the “.xlsx” file into the list of strings format. The “xlwings” module reads the “.xlsx” Excel file using the “Book()” function with aggregation with the “sheets” attribute and opens the same sheet on the active local application. The “.xlsx” workbook utilized here contains only one sheet. Within the range() function provide the sheet information to get the data, and to implement utilize the “value” with dot(.) notation.
Output
The “xlwings” module will read a “.xlsx” file and parse the content of the Excel sheet into the lists of strings:

This article is about how to read a .xlsx file using the pandas library in iPython.
Bonus Tip: Python vs IPython
Python is the general-purpose programming language whilst iPython is the interactive command shell meaning that iPython provides an interactive user experience to perform the computationally expensive exploratory analysis and vistualization. In addition, the iPython Notebook user can execute the command and get the output right at the instance upon execution. Moreover, the IPython provides robust “Error Tracing” information that is beneficial in tracing the error.
Conclusion
To read a “.xlsx” file using the pandas Library in iPython all the user needs to do is launch the iPython (Jupyter Notebook) then, load the “.xlsx” file into the script using the “excel_read()” function. Another approach to reading the “.xlsx” file is by utilizing the pandas built-in “openpyxl”, and “xlwings” modules. Or direct reading in pandas via the “ExcelFile()” function. This article has demonstrated the prevalent approaches to reading a “.xlsx” file using the pandas library in iPython.