
Pandas DataFrame is the 2-dimensional array having all information about data, features/columns names, and index labels. During the data analysis, Pandas DataFrame gives flexible access to manipulate the data according to the needs. However, most of the time, there is a need to update the values, for instance, where DataFrame contains “NaN” values in their columns. In such a scenario, the user wants to select multiple columns in DataFrame to manipulate the data accordingly.
This article is about selecting multiple columns in a Pandas DataFrame.
How To Select Multiple Columns In a Pandas DataFrame?
Most of the time while cleaning data or performing data wrangling there is a need to manipulate the values like “Null”, “NaN”, or “None” with some representable, numeric information. For this purpose, selecting multiple columns may required. To select multiple columns in a Pandas DataFrame, follow the below-listed approaches:
- Select Multiple Columns Using the Index Operator
- Select Multiple Columns by Specifying the Position of Columns in DataFrame
- Select Multiple Columns by Specifying the Column Names of the DataFrame
- Select a Column by Fetching the Column Name in the DataFrame
- Select Multiple Columns by Index Slicing Approach
- Select Multiple Columns by Dropping the Column From the DataFrame
- Select Multiple Columns And Swap their Position in Pandas DataFrame
- Select Multiple Columns by Using the “difference()” Function
- Select Multiple Columns By Using the “isin()” Function
- Select Multiple Columns by Index Slicing Approach
- Select Multiple Columns Using the “filter()” function
Approach 1: Select Multiple Columns Using the Index Operator
The “Index Operator” is used in Pandas to access the index or position of the list, array, or characters. In Python, the “Index Operator” uses the square brackets “[ ]”. While selecting multiple columns in a DataFrame user can utilize the “index” operator in Pandas DataFrame. To do so, the user selects the multiple columns and encloses them within the list containing a string:
import pandas as pd
# considering a sample DataFrame
df = pd.DataFrame({'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']})
# select columns
Selecting_multiple_columns = df[['library', 'canteen']]
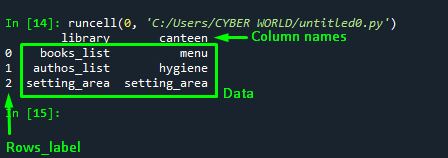
print(Selecting_multiple_columns)Output
The output shows that the new DataFrame contains only the two selected columns “library”, and “canteen”. The “cultural society” column has been eliminated from the DataFrame:
Approach 2: Select Multiple Columns by Specifying the Position Of Columns in DataFrame
Users can choose the particular columns using the index slicing approach. However, to select multiple columns, the “iloc” is used with the created DataFrame using the dot(.) notation. The “iloc” attribute in Python takes an integer value as an input. Within the brackets “({ })” pass the rows and columns information. Here’s how you can select multiple columns in a Pandas DataFrame:
import pandas as pd
# consider a DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million','4.4 million', '870,000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select columns
Selecting_multiple_columns = df.iloc[:, [0, 1]]
print(Selecting_multiple_columns)In the example code, using the index slicing (m,n), all the rows are included in the new DataFrame, and for selecting multiple columns the list is utilized. Within the list (take integers as input), the index position of the multiple columns is specified, separated by commas (,).
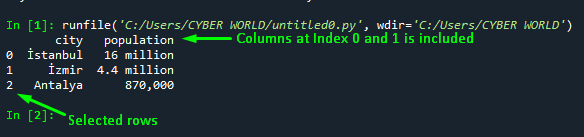
Output
The output of the above code shows that all the rows and selected columns at index 0 and 1 are included in the DataFrame:
Approach 3: Select Multiple Columns by Specifying the Column Names of the DataFrame
To select multiple columns the user can utilize the “loc” attribute with the DataFrame using the dot(.) operator in Python. However, to implement the “loc” attribute for selecting multiple columns in a Dataframe, the user needs to pass the particular column name within the list as a string and separate them with the “colon (:)” operator for string slicing.
The “loc” reads the column names includes them in the string and returns them on output. To select the desired rows, the same “colon(:)” approach is followed:
import pandas as pd
# consider a sample DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million','4.4 million', '870,000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select multiple columns
Selecting_multiple_columns = df.loc[1:2, 'city':'population']
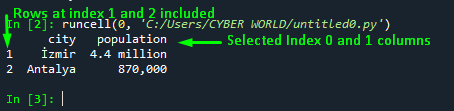
print(Selecting_multiple_columns)Output
The below snap is the output of the above example code, depicting that two rows and columns have been selected from the original DataFrame:
Approach 4: Select a Column by Fetching the Column Name in the DataFrame
Users can extract a particular column from the entire DataFrame, using the “loc” attribute in Python. The “loc” attribute in Python is enclosed with the square brackets “[ ]” and takes an integer value as input:
import pandas as pd
# consider a sample DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million', '4.4 million', '870000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select multiple columns
Selecting_multiple_columns = df.loc[1, :]
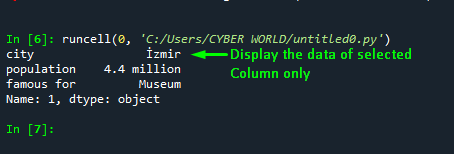
print(Selecting_multiple_columns)In the example code, the [1,:] notation depicts information that the “loc” attribute selects the column at index location 1 and includes all the rows.
Output
The below snap is the output of the above example code:
Approach 5: Select Multiple Columns by Index Slicing Approach
Using the “iloc” attribute, you can select the multiple columns in Pandas DataFrame. Within the square brackets index a particular range of the rows and the columns with the help of colon(:) notation and separate them with commas(,):
import pandas as pd
# consider a sample DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million','4.4 million', '870,000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select multiple columns
Selecting_multiple_columns = df.iloc [0:2, 0:2]
print(Selecting_multiple_columns)In the above example code, the approach is to select multiple columns from the original DataFrame using the index slicing within the “iloc” attribute. The index slicing [0:2] notation, includes the element at position “0”, but the element of the colon(:) is excluded from the final DataFrame.
Output
The below snap illustrates that the new DataFrame contains the two selected columns and the rows:
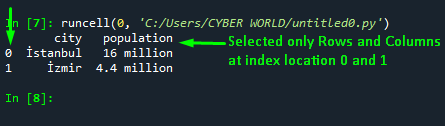
Approach 6: Select Multiple Columns by Dropping the Column From the DataFrame
Another practice is to select multiple columns by implementing the “drop()” function on the DataFrame. The “drop()” function will remove the selected columns from the original DataFrame. To implement the drop() function on the DataFrame, you need to pass the selected columns variable and specify the axis.
For selecting multiple columns from the DataFrame the axis must equal 1 (axis=1):
import pandas as pd
# consider a DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million','4.4 million', '870,000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select multiple columns
multiple_col = ['famous for', 'population']
multiple_col=df.drop(multiple_col, axis=1)
print(multiple_col)The above example executes in such a way that the selected columns are dropped from the original DataFrame and the other columns’ information is displayed on the output.
Output
The output shows that the column selected in the “multiple_col” is dropped from the dataframe and the desired column is displayed on the output:
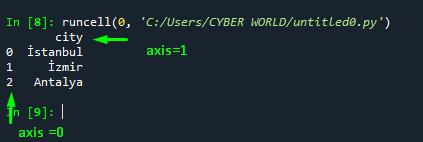
Approach 7: Select Multiple Columns and Swap their Position in Pandas DataFrame
Sometimes, the user wants to swap the column’s position in the DataFrame by selecting multiple columns as their desired sequence. To implement the multiple-column swapping, utilize the “reindex()” function:
import pandas as pd
# construct a DataFrame
df = pd.DataFrame({'city': ['?stanbul','?zmir','Antalya' ],
'population': ['16 million','4.4 million', '870,000' ],
'famous for': ['The Blue Mosque', 'Museum', 'Hadrians Gate' ]})
# select columns
multiple_col=df.reindex(columns=['population', 'city', 'famous for'])
print(multiple_col)In the above example, the selected column sequence is passed within the “columns” parameter of the reindex() function.
Output
The output shows that the order of the columns is swapped accordingly in the “columns” parameter:
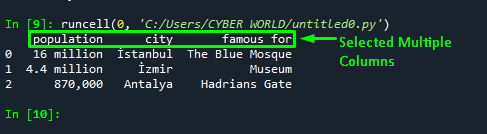
Approach 8: Select Multiple Columns by Using “difference()” Function
The “copy()” function in the Pandas DataFrame is used to create a duplicate copy of the original DataFrame. The attributes passed within the square brackets, and the “difference()” function aggregately perform the task of selecting the multiple columns and then dropping them from the created copy of the original Dataframe and displaying the modified column:
import pandas as pd
# consider a DataFrame
df = pd.DataFrame([['?stanbul','?zmir','Antalya' ],
['16 million','4.4 million', '870,000' ]],
columns=['city','population','famous for'])
print("original DataFrame: \n", df)
# select columns
droping_col = ['famous for','population']
multiple_col = df.copy()[df.columns.difference(droping_col)]
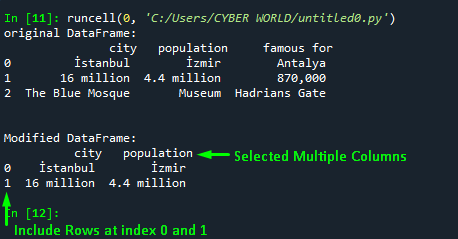
print("\n\nModified DataFrame: \n", multiple_col)Output
The below snap is the output of the above example code:
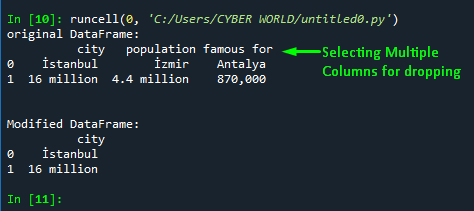
Approach 9: Select Multiple Columns By Using the “isin()” Function
To select multiple columns in a Pandas DataFrame, the isin() function can be utilized. To implement the “isin()” function, the user needs to invoke the “columns” parameter with it. And within the isin(), pass the selected columns in a list as a string:
import pandas as pd
# consider a DataFrame
df = pd.DataFrame([['?stanbul','?zmir','Antalya' ],
['16 million','4.4 million', '870,000' ],
['The Blue Mosque', 'Museum', 'Hadrians Gate' ]],
columns=['city','population','famous for'])
print("original DataFrame: \n", df)
# select columns
multiple_col = df.loc[0:1, df.columns.isin(['city', 'population'])]
print("\n\nModified DataFrame: \n", multiple_col)The “loc” attribute selects the multiple columns and rows by using the “index []” operator. Select the rows from the [0:1] range using “colon(:)” notation and for selecting multiple columns the “isin()” function is utilized along with the “columns” parameter.
Output
The below snap illustrates the output of the above example code, returning the multiple selected columns of the DataFrame:
Approach 10: Select Multiple Columns by Index Slicing Approach
Instead of creating a DataFrame, the user can load and read the DataFrame into the Python Script. To do so, the pandas “read_csv” function is used. Within its parentheses passed the dataset of “CSV” format. This will transform the dataset into the DataFrame:
#import pandas library as pnd to the Python script
import pandas as pnd
#reading dataset with pandas library
df = pnd.read_csv ('tested.csv')
#head() displays the first 5 rows from the dataset on the console
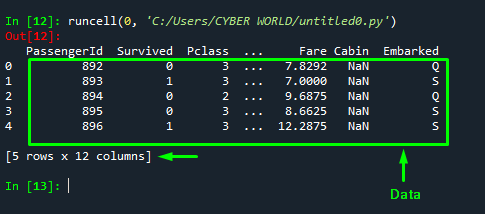
df.head()Output
Reading the DataFrame in Pandas library using the “read_csv()” function:
Approach 11: Select Multiple Columns Using “filter()” function
Another practice to select the multiple columns in the Pandas DataFrame, utilize the Python in-built “filter()” function. Within the filter() function pass the list of strings containing selected column names enclose all in the brackets “[ ]” and separate them with commas (,):
Selecting_multiple_columns = df.filter(['PassengerId', 'Survived','Pclass','Name', 'Age'])
Selecting_multiple_columns.head()Output
The filter() function removes the other columns from the DataFrame and returns the selected columns in the modified DataFrame on the output:
This article is about selecting columns in a Pandas DataFrame in Python.
Conclusion
To select the multiple columns in a Pandas dataframe, first, construct the DataFrame or load the dataframe using the “read_csv()” function, then using the inbuilt function and attributes make a selection on columns. Users can utilize, filter(), difference(), reindex(), and drop() functions or use the “index [ ]” operator to select multiple columns in a Pandas DataFrame. This article has demonstrated the approaches to selecting multiple columns in a Pandas DataFrame.